

デスクリサーチをベースとした市場のトレンド分析を元に、サービス / プロダクトの改善・開発を行います。未来の生活者や市場動向を事業に活用したいクライアント様向けのパッケージとなります。
データ、というと商品の市場占有率や売上高など数値として把握できる定量データのことをイメージする人が多いのではないかと思います。
かつてBtoBのメーカーで商品開発をしていた時も、私は自社内にある定量データから根拠を作って商品開発をしていました。
では、全く新しいコンセプトの新商品や、市場を創りにいく新規事業の開発に活用できるデータとはどういうデータなのでしょうか。
定性データを活用する
SEEDERでは、新商品 / 新規事業開発のアイデアソースとしてN数の少ない定性データを活用して企業をご支援しています。
先進的な生活者 ” トライブ ” の価値観を抽象化しインサイトを抽出し、組み合わせて未来洞察をしています。
なぜN数の少ないデータを使うのか?
世の中にはたくさんの定量的なトレンド・データがありますが、例えば、アメリカの「禁酒トレンド」をそのままインプットするだけではそこから商品開発の具体的な示唆を得ることは難しいと思います。
例えば以下の定量レポートから、商品の具体的なアイデア発想ができるでしょうか。
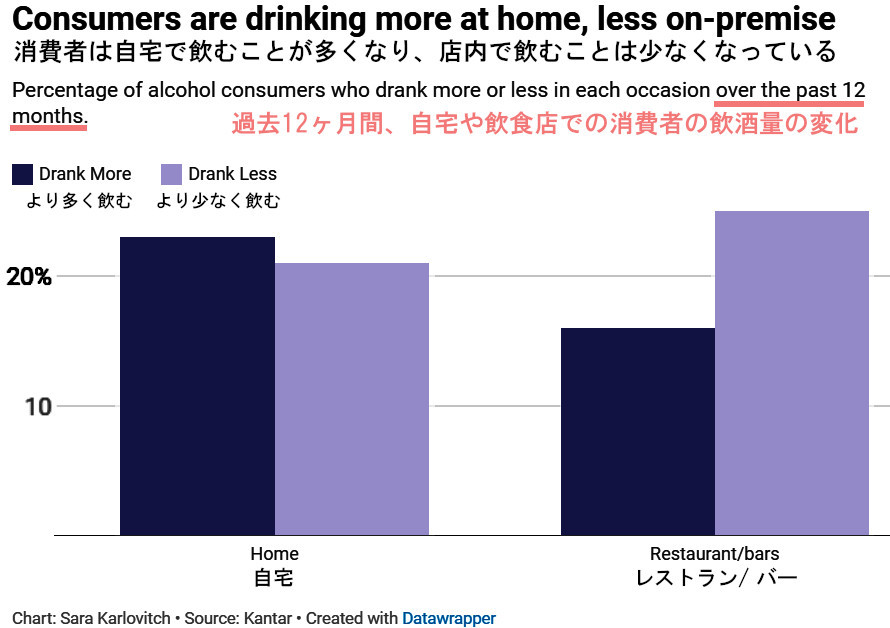
Kantarの最新レポート、“Shopping for Beverage Alcohol 2023”(アルコール飲料の購入)によると、過去12ヶ月間に自宅でより多くお酒を飲んだ消費者は23%であるのに対し、バーやレストラン店内でより多くお酒を飲んだ消費者は16%、とのこと。つまり、いわゆる「宅飲み」する人々の方が、より多くお酒を飲む傾向に。また、その逆に、同じ期間に自宅でお酒を飲む量が少なかった人々は21%、バーやレストランでお酒を飲む量が少なかった人々は25%。いずれも2割以上もの人々が、お酒を飲む量を抑えていたことになりますが、特に、バーやレストランなどのお店で飲むのを自制していた方々は、25%、実に4人に1人の割合ということになります。
https://www.marketingdive.com/news/alcohol-purchasing-marketing-gen-z-2023/649546/
上記の「宅飲み需要の増加」というトレンドから、ビールメーカーや飲料メーカーがどういう商品のコンセプトが想定できるか。以下のような補足的・付随的定量情報を加味しても商品アイデアが着想できるでしょうか。
- 世界的な健康意識の高まり
- 日本食やハーブなどを活用したヘルシーな飲食料品の需要の拡大
- 特に若い世代での、アルコールを含まない選択肢への興味の増加

定量的なデータから具体的なプロダクトのアイデアの示唆を受けることは難しいと思います。どうトレンド情報を組み合わせてもそれは結局仮説でしかなく、根拠に乏しいものになってしまいます。
「特定の誰か1人を喜ばせること」
様々な商品やサービスのほとんどは「特定の誰か1人を喜ばせること」が発想の起点になっています。ペルソナ設定などで年代やライフスタイルを具体的に想像するのもそのためですが、何もない”ゼロ”の状態からで商品やサービスを開発するにはN-1のデータが使えます。

上の図で例えば左側の、中国の一級都市に住んでいる20-30代の子どもがいる女性1000人をターゲットとした商品を開発するとコンセプトは平均化された凡庸なものになってしまい、競合との差別化が難しい商品になってしまいます。
一方で右側の、四川省在住のLさん、3歳の娘を育てる29歳のお母さんをターゲットとすれば他社サービスや商品との差別化が可能なプロダクトを開発できます。
アイデアは、具体的なN-1から得られる

N-1マーケティングで知られる西口氏の著書には以下のようの書かれています。
「アイデアを出すために大勢で集まってブレストやディスカッションをしても、有益な案は見つかりません。ブレストでは既視感が会ったり、単に奇抜なだけだったりと、商品提案しても広告訴求としても実現できないような案ばかりが多く挙がります。その理由は、ブレストで想定する顧客像に具体性がないからです。
…….
商品やサービスに、届けたい顧客がいる以上、マーケティング上で機能する強いアイデアを導き出すには、実在する1人の顧客を深堀りすることが唯一有効な方法です。
トライブを捉えることが効果的

そこで私たちは、トレンドをそのまま扱うのではなくその背後にある価値観を持つ生活者をトライブとして定義します。
すると開発に示唆を与える生活者インサイトの調査が可能になります。

N数が少ないデータで大丈夫なのか?
敢えて反論を挙げるとすると、お客様に言われるのが「N数の少ないデータで信頼できるのか?一部の尖った人の感覚的なものばかり参照してしまうことにならないか?」ということです。しかし、
どの市場においても、調査対象者数を増やすほど、手に入る情報が減少することが立証されています。
https://www.nngroup.com/articles/why-you-only-need-to-test-with-5-users/
リサーチによるユーザー起点マーケティングで世界的に著名なニールセン・ノーマン・グループの調査によると
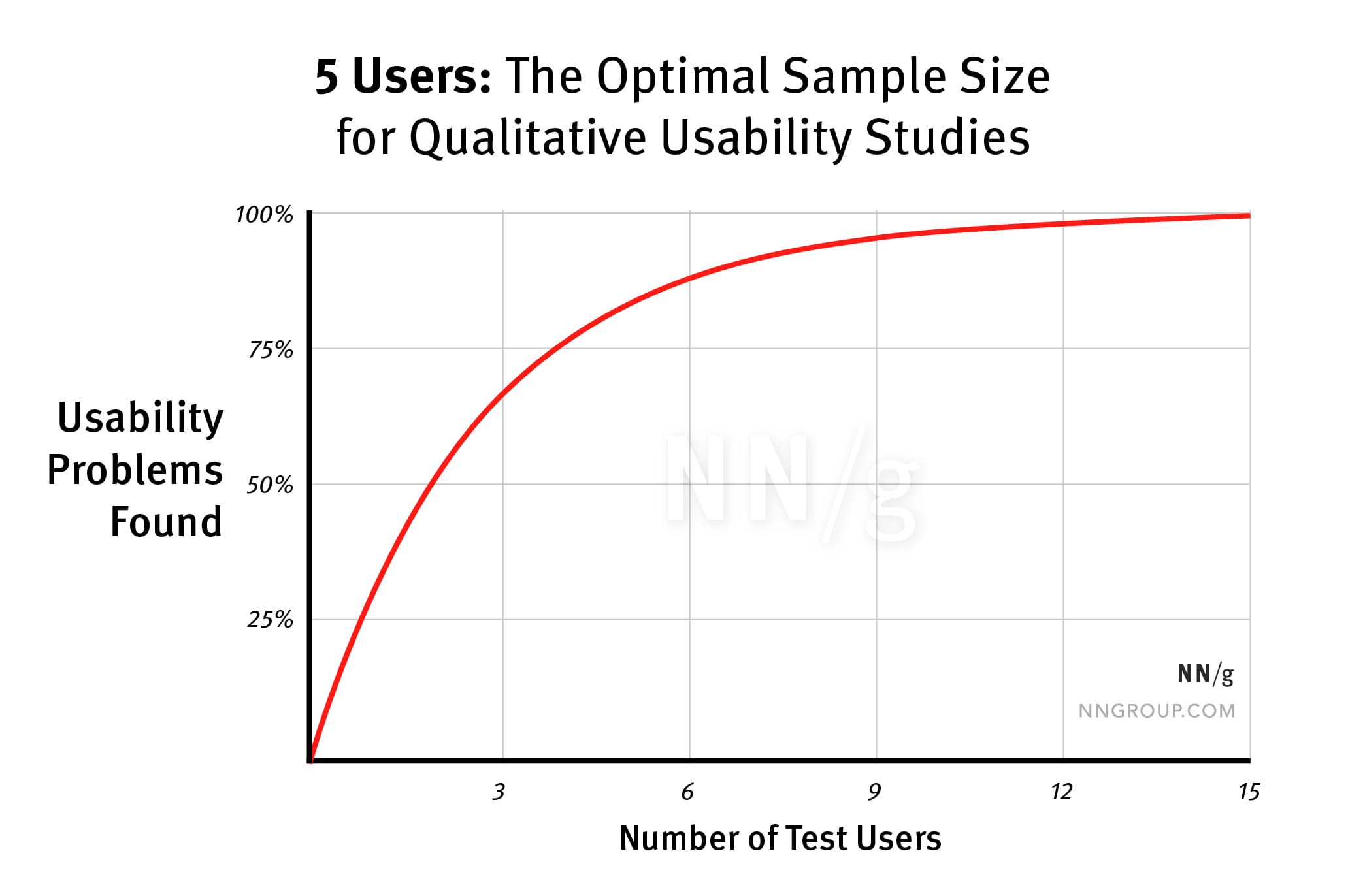
- ユーザーの数が増えるにしたがって、学べることは減少する。なぜなら同じ現象を繰り返し見ることになるからである。同じことを何度も見続ける必要はなく、正しい質問を5人に投げかければ、80%程度は理解することが可能である。
- 上記の図の通り、1人に話を聞くという行為を行うだけで、非常に多くの新しい情報を入手可能と考えられている。(1人で30%)さらに2人目に話を聞くと、1人目との共通項が多く見つかることがわかる(2人で50%)。
と報告されています。
SEEDERでは質問項目を入念に検討し、トレーニングを詰んだインタビュアーが1人あたり60~120分の*デプスインタビューを行いユーザーから一義的な情報を吸い出しています。
* デプスインタビューは限られた時間でインタビュイーと信頼関係(ラポール)を築き、意思決定のキーになったポイントなどを先入観なく引き出すことが求められるので相応の準備とトレーニングが求められます。
こうしたN-1リサーチによって、開発するプロダクトに求められる、ユーザーに本当に必要な機能の仮説づくりに役立てていきます。







